A little history

The Ensoniq SD-1 is a synthesizer from the 1990s — a ROMpler with a Motorola 68000 at its heart. Like many synthesizers of the era, it uses the cheap, easy, and simple storage medium of the day: 800K floppy disks for storage of everything: factory programs, user programs, presets (organized small sets of programs), full-up MIDI sequences, and its own operating system.

The format is proprietary and somewhat peculiar: a custom FAT, 10 sectors per track numbered 0 through 9 (not 1 through 10 like a PC), big-endian multi-byte fields throughout, and a handful of file types that the rest of the computing world has never heard of. To retrieve your data on a modern computer, or to get sounds back onto the synth, you need something that can speak this format.
Few if any USB disk drives can handle this format; the extant programs which can read Ensoniq disks all run under MS-DOS (or Windows DOS emulation) and need a real, wired-in diskette drive to handle reading and writing disks. Forget about doing this on a Mac.
Fortunately, the SD-1 has a reasonably robust MIDI system-exclusive, or “SysEx”, implementation, capable of dumping and receiving pretty much everything except the actual sequencer OS that can record sequences to the SD-1’s internal memory and play them back. Those of us who saw the handwriting on the wall (and who didn’t want to keep a 486 tower lying around just to write the floppy disks that were becoming harder and harder to find anyway), took the earliest possible opportunity to dump everything out over SysEx and save it elsewhere.
Getting the sequencer OS back into the thing still needs a diskette, which is an issue (solved by third-party add-ons that could store hundreds of floppy images on a USB stick).

The renaissance
But there was some big news in March 2026, that made the question of accessing the SD-1’s disks and data an interesting topic again.
The folks at Sojus Records announced a wrapper around the previously-created SD-1 MAME emulator that allowed the SD-1 to be loaded as a VST3 plugin.
For all of us who had SD-1’s (or who still have them, but have shifted to much-more-convenient computer-based sequencing), this was a sit-up-and-take-notice moment. Our baby was now a plugin! And all that work we’d done previously was now usable again.
However! The first release of the plugin was only able to read .IMG files — a file format created by Gary Giebler to store floppy images on disks other than floppies. This meant that there needed to be a way to get .syx SysEx files back onto .IMG images so they could be used once more.
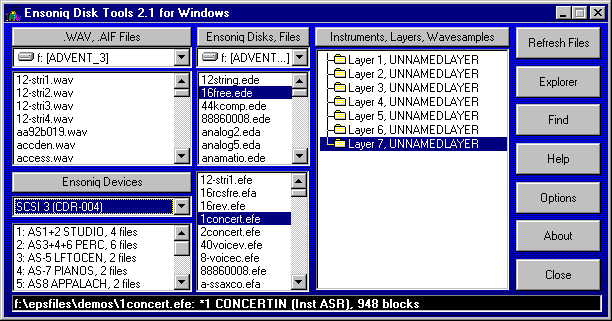
Sure, the Giebler and Rubber Chicken utilities were still out there, but I’m a Mac guy, and attempts to get those running properly on emulated MS-DOS were pretty much a failure. What I needed was a utility that could read and write disk images on my Mac.
A year ago I would have looked at that and said, “man, I do not have the time or the patience to read all those Transoniq Hacker articles and try to piece this together.” This year, I didn’t have to have that patience: I had Claude, and $20 worth of tokens a month to spend, so I thought, why not? This is actually a fairly well-defined problem:
- Documentation for the disk organization and file formats exist in this PDF archive of the Transoniq Hacker
- We have some disk images that we know work with the emulator, including a sequencer OS disk
- The emulator seems to be able to read
.IMGfiles fine, so if I can figure out how to write disks, I should be able to read them on the emulator.
This is a pretty solidly mapped-out basis to start from, and I figured that with both good documentation, sample data, and a working system to test against, I stood a pretty good chance of being able to carefully steer Claude to a solution.
Getting started
I decided that I wasn’t going to be fancy here. This is going to be called sd1diskutil because it’s just going to be a wrapper around a library that knows how to do the job.
So on March 26th, I sat down with Claude in the terminal, loaded obra/superpowers, and started brainstorming. I decided that, contrary to my more recent utility projects, I’d try to produce something that could be embedded into a prettier interface than just the command line.
That meant the first decision was to what language to implement this in, and after some discussion with Claude, we settled on Rust, to allow me to make this a functional programming approach, using very tight types and operations on them. This was, in hindsight, probably colored by my experiences with Scala and really tight types, and how that made it so much easier to write correct code.
To go with that and make it usable, we came up with a very thin CLI binary (sd1cli) that could convert MIDI SysEx dumps to and from the SD-1’s on-disk binary format provide full disk management — list, inspect, write, extract, delete, create.
Because I knew that eventually I wanted to wrap this up in a pretty UI, I asked Claude how to build Swift bridging in, and it included a clean UniFFI surface for SwiftUI, allowing the same library to eventually power a macOS application.
I knew that I was going to have to be very careful to implement this correctly. File systems and custom file formats are not forgiving, and the SD-1’s OS, though quite capable, is not what you would call robust.
- The architecture therefore mirrored the data as closely as possible and tried to ensure that everything was as safe and stable as possible:
DiskImageowns the raw 819,200-byte image.FileAllocationTableis a stateless handle that operates on a&mut DiskImageto avoid Rust borrow conflicts.SubDirectoryfollows the same pattern.SysExPacketis the only place nybble encoding and decoding happens — every layer above it works in plain bytes.- Atomic writes everywhere: save to a temp file, then rename.
I started out with a blank disk template created by the SD-1 emulator. What better source for a good disk than the emulator itself? (Oh, you sweet summer child. We’ll spend about three days beating our heads against this disk image.)
The first working implementation was achieved in a single burst: we planned out the types and operations, reviewed the design, and then built an implementation plan: workspace scaffold, error types, disk image, FAT, directory, SysEx parser, domain types, the full CLI. Integration tests for every command. The code compiled. The tests passed.
Then came the reality checks.
Block 4? Or block 5?
The Giebler articles said that the FAT should be at block 5. But our empty disk image from the emulator said it was at block 4. Everything else matched up: ten blocks long, 170 three-byte entries each. What was the problem? We could write files with our code to the blank image, and the SD-1 emulator could read them.
Figuring this took way longer than it should have, for a reason that only became clear in retrospect.
The blank disk template used during early development, as mentioned above, had been written by the Sojus VST3 plugin, which it turned out was concealing a sector-shifting bug that was actually happening at the underlying MAME emulator level!
See, normal DOS disks have 11 sectors per track, numbered 1 through 11. The SD-1 disks have ten, numbered zero to 9! MAME does handle the ten sectors per disk thing fine…but it uses SD-1 blocks 1 though 9, dropping block 0 and adding an empty all-zeroes block 10. So a fresh emulator-written disk has its FAT at block 4 instead of block 5. And a freshly-written emulator disk also immediately throws a DISK ERROR – BAD FORMAT if you try to read it…but we were only trying to write it, thereby breaking it, and then read it with our Rust code!
The Giebler article in Transoniq Hacker said block 5 and our write code was written to put it at block 5, which was correct. The disk from the emulator said block 4, because the emulator dropped block 0. The emulator could read the test disks written by our code fine — because sd1diskutil‘s own writes were correct.
But whenever the emulator saved a file back, it would quietly apply the shift again, moving the FAT back to block 4, exactly matching the initial (broken, but we didn’t know it) blank disk. So we went round and round, trying to resolve this: the article says 5, the disk says 4, the emulator reads 5 and writes 4, maybe both are correct and the article didn’t have that, so we should support either, or…?
I repeatedly tried to add files to the disks written by the emulator, and they always got DISK ERROR – INVALID FORMAT. How was I screwing this up?
I finally figured it out when I wrote a file to a good (block-5) disk and immediately tried to read it back (from the now block-4 disk). The emulator immediately threw a BAD DISK error…on its own output! So the emulator was wrong (though at the time we didn’t know why — see below!), and the article was right.
We created an empty disk by taking a copy of the known-good SEQUENCER-OS disk and deleting all the files from it using our code. We then wrote a single file to it and tried it on the emulator…and the disk was readable and the file was there.

Other early problems and fixes followed the same discipline of checking what we wrote against the emulator: local filenames needed to be forced to uppercase because the SD-1’s LCD doesn’t render lowercase. We had to analyze AllPrograms and AllPresets files on the SD-1 SEQUENCER-OS disk to figure out how to write them, and analyze how these were encoded into SysEx types (the SD-1 MIDI implementation helped some, but a lot had to be worked out from just trying things until we worked them out). The free block count management logic needed a rewrite. Each fix came from trying it and checking it against what the emulator would accept, not just blindly accepting the documentation, useful though it was,
The Program Interleave Bug
Of all the bugs, the program interleaving bug was the most insidious and hardest to fix, because it was wrong in a way that “worked”. Nothing broke, the OS didn’t complain, and on first glance seemed to be completely reasonable and perfectly correct…but sequences played back with all the wrong programs if they were being loaded from program memory. (ROM patches were fine.)
Programs stored in a SixtyPrograms file are byte-interleaved on disk: there are two independent 15,900-byte streams packed together, with the even byte positions carrying programs 0 through 29, and the odd byte positions carrying programs 30 through 59.
The original SysEx-to-program bank implementation had picked then outas alternating pairs — taking a program from the first half for bank 1, program 1, then a program from the second half for bank 1, program 2, and so on. The result was that programs were extracted perfectly, but landed at the wrong bank and patch position.
I was able to figure this out by loading a custom 60-sequence file with 60 embedded programs, playing it back, and seeing that the expected patches were there but in the wrong places. Unfortunately, the fact that the last time I’d actually looked at these sequences was 2010 or so meant that I didn’t remember where the right position was! I knew they were wrong because they sounded wrong, but not where the right place was.
It wasn’t until I found a SysEx dump of one of the factory sample sequences that we were able to write that to a .IMG and load it, then compare the locations where the programs went when our file was loaded in contrast to where they ended up when they were loaded from the SEQUENCER-OS disk by writing them down by bank and slot both ways and letting Claude figure out the mapping, which it did quite nicely.
Extracting the even and odd byte streams in both the file we wrote and the “good” on-disk one, and then searching for known program names within each stream, allowed Claude to find where the one patch I definitely knew the sequence used was in both sets of interleaved data and then derive the correct mapping: a first-half/second-half split rather than alternating pairs.
In the process of figuring all this out, we created a Python analysis tool, dump_programs.py, which could extract and list individual programs from multi-program SysEx dumps and disk files. Once we verified the extraction algorithm in the Python code, we were easily able to replicate it in Rust, and test it with two other sequence-and-program dumps by verifying they played back correctly on the emulator after being written to disk from a SysEx file.
Sequences and a Deeper Problem
Extracting sequences revealed a gap in the implementation: we could write SysEx files containing sequences and patches, but we couldn’t read them. There was a function that converted SysEx to the on-disk representation, but nothing that went the other direction.
We discovered this when we realized that extraction was wrapping raw disk bytes in a SingleSequence SysEx header and producing output twice the expected size. Proper test-first setup allowed us to easily implement this properly, writing a 60-sequence-and-program file to disk, verifying it sounded correct on the emulator, and then reading it back out to .syx, verifying that the new file was a byte-for-byte match against the original.
At this point, I wrote up the block-4/block-5 bug for the Sojus folks to take a look at on GitHub. (At this point I knew that there WAS a bug, but not WHY there was a bug.) They got back to me very quickly, and confirmed that yep, the emulator was screwing up the disk, and why.
The plugin routes all floppy writes through MAME’s get_track_data_mfm_pc, a function that expects PC-standard sector numbering (1–10). As mentioned, the Ensoniq format uses 0–9. MAME silently discards sector 0 of every Ensoniq track, shifts the remaining sectors down by one, and zeros the last slot! Once the emulator rewrites the track, every block on the track contains wrong data, and every tenth block is zeroed. This was the same bug that had broken the early blank disk template and sent us chasing the wobbly FAT location for days — now fully understood, and confirmed with the Sojus developers, who identified the affected code as esq16_dsk.cpp in MAME — the DOS-to-Ensoniq-and-back block mapping.
They’re busy working that as of 3/28, but in the meantime, they found a workaround: the emulation code can also read HFE format files. HFE stores the raw MFM flux data and bypasses MAME’s sector enumeration and extraction entirely. Which is totally awesome…but the sd1diskutil code did not speak HFE, and I’d never even heard of HFE. Watching the wonderful Usagi Electric suss out data encoding has educated me a little bit on data transitions and stuff like that, but it wasn’t something I was ready to work on myself at all!
Archaeology Before Engineering
Fortunately, the Sojus folks had an HFE image with some data on it to test with: two single patches (OMNIVERSE, SOPRANO-SAX) and a 60-program file. Claude and I embarked on trying to make sense of the data in this file, and this is where Claude seriously impressed me.
We started off with this HFE file. We knew basically that it should have MFM data in it, and nothing else. Claude bootstrapped up from knowing what MFM data should look like to actually finding it in the file and making sense of this otherwise opaque stream of bits!
Claude’s first attempt at locating sector headers found nothing. The standard MFM A1* sync marker should have been there ([0x44, 0x89]) but did not appear anywhere in the file. Claude figured out that this was because HFE stores bits LSB-first per byte, in the order the read head encounters them. The standard representation is MSB-first, so at first glance the data made no sense. Claude tried a bit-reversed version of the data, then a bit-reversed-per-byte version, and found the sync marker! [0x22, 0x91], with each byte bit-reversed.
Once that hurdle was crossed, it was simple for Claude to find the markers and decode all 1600 sectors. The FAT free count in the decoded image matched the hardware OS block count: 1510. The block-to-sector mapping was confirmed against blank_image.img:
block = track × 20 + side × 10 + sectorTrack geometry was pinned down: each side of a track is exactly 12,522 encoded bytes. The fixed preamble (Gap4a, sync, Gap1) consumes 284 bytes. Each of the 10 sectors is 1,148 bytes with a fixed structure. The remaining 758 bytes are inter-sector gaps — 75 bytes for sectors 0 through 8, and the rest absorbed by sector 9.
I would have taken quite a long time and a lot of poring over the MFM spec and a lot of trial and error to figure this out, if ever, and Claude had it all doped out in half an hour or so.
At this point Claude knew how to read an HFE file but not what we should do with it.
We invoked the brainstorm/design spec/implemetation plan path again. I proposed that what we needed was a translation layer: just get the HFE image to an IMG image, and all of our tools could easily handle it. To use it on the emulator, we’d just convert the IMG image back to HFE, which the emulator should safely be able to read and write.
Superpowers wrote a complete design spec before any Rust code was touched, pulling in all the information Claude already had at hand about how the HFE files work, writing Python code to cross-check assumptions made in the spec: exact constants, the complete MFM encoding rules, CRC16-CCITT coverage, the interleaved side storage layout, error variants, test cases, the works.
Then superpowers wrote the implementation plan, with concrete function signatures, and specific expected outputs, all properly built as functions on types and easily testable.
HFE Implementation, going full vibe
At this point it was Claude’s party. I had read the spec and the plan, and everything looked reasonable, but I didn’t really know the HFE spec solidly enough to critique the code.
Claude created three new error variants: InvalidHfe, HfeCrcMismatch, HfeMissingSector, each carrying track, side, and sector context so errors are never ambiguous. Then hfe.rs itself: 771 lines creating the full encode/decode pipeline, and new CLI subcommands hfe-to-img and img-to-hfe to encode and decode HFE images.
The superpowers code review caught one bug: header offset 17 — the “do not use” field in the HFE v1 spec — was being written as 0x00. The spec requires 0xFF. A strict HFE reader would reject the file, and we knew the right answer, so…easy fix.
After implementation, the code passed all the low-level tests, and read_hfe on the sample HFE file properly decoded all 1600 sectors, returning a DiskImage whose directory listed OMNIVERSE, SOPRANO-SAX, and 60-PRG-FILE with the correct free block count. A complete round-trip from .img to HFE and back produced a byte-for-byte identical result.
The Acid Test
The final test of the HFE pipeline started with the Sequencer OS disk: an 800K image containing every file type the SD-1 supports: Thirteen OneProgram files. Eleven SixPrograms banks. A ThirtyPrograms bank, eight SixtyPrograms banks, four TwentyPresets banks, eight sequence files of various sizes, and the sequencer OS binary itself (656,384 bytes!), totaling forty-nine files, and leaving just five free blocks.
The disk was encoded to HFE and loaded into the emulator. Success! The emulator accepted the disk, an everything was present. I selected the sequencer OS, hit load, and it was loaded successfully. A previously-loaded sound bank in emulator memory contained a program named GREASE-PLUS, definitely not one already on the disk. I saved it to the HFE disk, and it wrote successfully.
We decoded the modified HFE file to an IMG and listed the contents: fifty files. Three free blocks. GREASE-PLUS in disk slot 13, a OneProgram file, two blocks. Complete success!
Future Plans
Now that this is done, I plan to release it on GitHub as a library. If I get around to writing the pretty GUI, I will probably see if I can sell that, because why not? The Giebler disk utilities still sell for $60!
At any rate, the CLI will be out there and should work, for anyone who wants to build it themselves.