This is the cycle() function from “two queues as a stack”, but I somehow had some problems getting it right out of the gate.
It’s the same basic thing: if the list is empty, you’re already done. Else, pop a node off the old list, push it onto the new one, return the pointer to the new list.
/**
* Definition for singly-linked list.
* type ListNode struct {
* Val int
* Next *ListNode
* }
*/
func reverseList(head *ListNode) *ListNode {
if head == nil {
return head
}
var newhead *ListNode
var p *ListNode
for {
if head == nil {
break
}
p = head // point to head of current list
head = head.Next // drop head node from list
p.Next = newhead // append new list to p
newhead = p // save new list
}
return newhead
}
Interesting scoring – top 77% CPU, top 66% memory.
Given a set of upper and lowercase letters, what is the longest possible palindrome for this set of letters?
I chose to do this with a pair of hashes to count the letters overall; the even counts can just be added. For the odd counts, add the largest count, then for the remaining counts, reduce them by one (since there has to be an even number of them to preserve symmetry), and add those to the total.
funclongestPalindrome(s string) int { // More breaking down into runes letters := []rune(s) letterMap := map[rune]int{} for_,c :=range(letters) { letterMap[c]++ } // any letter with an even count can be included // any letter with an odd number of occurrences // can be included if: // - it's even (so it's always symmetric) // - it's the letter with the largest odd count (also symmetric) // - it's a letter with at least a 3 count (once the largest odd // count is removed, reduce odd counts by 1 and they're // also symmetric) // Walk through the map and record // - the even counts // - the largest odd count // - the smaller odd counts, reduced by one palindromeLength := 0 largestOddCount := 0 varlargestOddKeyrune oddKeys := map[rune] int{} fork, v :=range(letterMap) { if v % 2 == 0 { palindromeLength += v } else { // odd. is this the largest odd count yet? if v > largestOddCount { largestOddKey = k largestOddCount = v } // Store the letter with it's count reduced by 1 // so it can be added symmetrically. oddKeys[k] = v-1 } } if largestOddCount != 0 { // there's at least one odd count. // delete the key of the max odd count, and add the count // to the palindrome length. palindromeLength += largestOddCount delete(oddKeys, largestOddKey) // the rest of the odd count letters can now be added. // the one-occurence letters/odd-occurrence letters // have been reduced by one, so either a) the count is // now zero, because there was only one occurrence of // the letter, or it's an even numer now (it would not // have been added if it was odd, and we reduced it by 1, // so it HAS to be even now -- whether zero or another even // number). for_, v :=range(oddKeys) { palindromeLength += v } } else { // there was no odd-numbered count, and we've already // added the even count. Nothing else to do. } return palindromeLength }
Scorewise, it’s not that great – top 67% in time, bottom 10% in memory, but it was done fairly fast, so I’m grading it acceptable. I think you could do better with arrays and converting the rune values to indexes, but this falls into the “yes, I could optimize it that way, but this will always work” category.
You have an N step staircase that you can climb either 1 or 2 steps at a time. How many ways are there to climb it?
It was clear that this was a recurrence relation, and my instinct was to cache the computed values. This would be a better attack for a more complex problem; this is just a Fibonacci sequence!
I did do the cached one first, and I am very proud of myself for properly passing the cache through:
func climbStairs(n int) int {
// this smells of caching...and a Fibonacci recurrence.
// we know that if we're at N, it takes 0 steps to finish.
// if we're at n - 1, there is one option: take 1 step.
// if we're at n - 2, there are two options, 2 1 step, or 1 2 step.
cache := map[int]int{
0: 0,
1: 1,
2: 2,
}
return assist(n, &cache)
}
func assist(n int, cache *map[int]int) int {
if steps, ok := (*cache)[n]; ok {
return steps
}
(*cache)[n] = assist(n-1, cache) + assist(n-2, cache)
return (*cache)[n]
}
A huge winner on runtime: 100%! But poor on memory: bottom 9%. An iterative Fibonacci calculation’s probably going to win on this one…Interestingly, it doesn’t! Runtime 82%, memory 33%.
func climbStairs(n int) int {
// this smells of caching...and a Fibonacci recurrence.
backTwo := 1
backOne := 2
sum := 0
if n == 1 {
return 1
}
if n == 2 {
return 2
}
for current := n; current > 2; current-- {
sum = backOne + backTwo
backTwo = backOne
backOne = sum
}
return sum
}
Off to the solutions to see what’s there.. the most compact iterative solution still isn’t any better on memory, but is the same speed as the cached one I wrote:
func climbStairs(n int) int {
next, secondNext := 0, 1
for ; n > 0; n-- {
next, secondNext = secondNext, next + secondNext
}
return secondNext
}
I’ll call this a win, and ++ for dynamic programming.
Given a magazine string, check to see if a ransomNote string can be composed by extracting characters from magazine. The count of ‘a’, ‘b’, ‘c’, etc. in magazine must be >= the count needed to compose ransomNote.
In another language, I might sort the strings and then compare them, but Go has no built-in string sorting, so putting the “I need to get this done” hat on, I chose building a map of characters in magazine and then progressively checking the letters in ransomNote to see if we either can’t find a needed letter, or run out.
I needed to go look up the syntax to convert a string to a rune array (it’s []rune(string), which is a weird-ass syntax), but otherwise it was pretty easy.
Not the most efficient possible: top 72% in speed, bottom 11% in memory, but I’d choose it if I was actually doing it in code I needed to get done. Also extremely straightforward.
Faster solutions take advantage of the characters a) being ASCII and b) being all lower-case; I’d argue against them in a real-world situation because any bad data would cause them to fall over with an array bounds issue. My solution could parse text in Nazca and still work.
func canConstruct(ransomNote string, magazine string) bool {
// Add the magazine chars to a map of map[rune]int, incrementing
// for each rune found.
// walk through the note, decrementing the char counts as we go.
// if we ever hit a rune that is not in the map, or whose count is 0,
// then return false. Else return true.
magazineMap := make(map[rune]int)
for _, c := range([]rune(magazine)) {
magazineMap[c]++
}
for _, c := range([]rune(ransomNote)) {
if _, ok := magazineMap[c]; ok {
if magazineMap[c] < 1 {
return false
} else {
magazineMap[c]--
}
} else {
// char not found
return false
}
}
return true
}
Given a function isBadVersion and a range of versions from 1 to N, find the lowest-numbered version that is “bad” as efficiently as possible.
This is another binary search, and I had a little less trouble with it. A few more and I’ll be able to knock one out right the first time. Since there weren’t any pointers or indexes or arrays to manage, this was easier. Still got tripped up on the order of testing, but when I sat down and delineated the terminal cases by hand I was able to easily code it.
Performance was excellent: 100% on CPU time, 95% on memory. Would be a win in an interview.
/**
* Forward declaration of isBadVersion API.
* @param version your guess about first bad version
* @return true if current version is bad
* false if current version is good
* func isBadVersion(version int) bool;
*/
func firstBadVersion(n int) int {
// Binary search it.
// n is candidate.
lowBound := 1
highBound := n
if isBadVersion(lowBound) {
// short-circuit: if lowest possible version is bad,
// no search is needed.
return lowBound
}
// Now search between the bounds for the switchover point. Low is good,
// high is bad.
for {
fmt.Println("Bad version between", lowBound, highBound)
midpoint := (highBound+lowBound) / 2
isBad := isBadVersion(midpoint)
if isBad {
highBound = midpoint
if midpoint == lowBound+1 {
// midpoint is 1st bad above lowbound (known good)
return midpoint
}
} else {
lowBound = midpoint
if highBound == midpoint+1 {
// midpoint is good, 1 above is bad, so that's it
return highBound
}
}
}
}
Weirdly, removing the debug made it slower. 81st percentile CPU.
Which pretty much goes to show that trying to rate efficiency of code via leetcode is probably a bad idea.
An old favorite, which I got at a Google interview. Not understanding the Google mindset at the time (2007 or so), I had my engineer hat on first, and pointed out that if you’re going to build a data structure, build the damn data structure. It’s ludicrous to build two stacks when you could build one queue in approximately the same amount of time.
However, the real purpose was “do you understand that pushing onto one stack and then popping items off onto the other reverses their order?”. Sure. OK. Fine. You could ask me “what would happen if…”, but no, it needs to be a no-one-with-any-brains-would-ever-do-this programming problem. (Again, this is a “let’s talk about your algorithm choices in our next 1-1” problem.)
Anyway, yeah. So I tried with arrays again to start and it was a huge PITA. I tried that for about ten minutes and said, forget this, I’m building it with linked lists.
So we have a Node that is added at the head to push, and delinked to its tail to pop. Easy-peasy.
The push operation just adds to the incoming stack, and doesn’t do anything else until we have our first pop, and which point we call the core routine here, Cycle. Cycle pops items one at a time off the in stack and pushes them to the out stack. Now a pop pulls the first item that was pushed, as required, since we’ve just reversed the in stack. I did have one error, caught in the submit, in that you don’t just check for the in stack being empty, but you also need to check for the out stack not being empty. If you don’t, you end up queueing an item out of order. Always wait for the output to be empty before actually cycling.
I did have to refresh my memory on adding a method to a struct – it’s func (this *Node) Cycle – but otherwise this was almost as much a breeze as the tree inversion.
I do need to do some exercises on managing arrays better, though — you can’t always use a linked list, especially if you need actual indexing.
Overall, pleased with the solution: 82nd percentile runtime, but 18th percentile memory. Might be better if I kept the popped nodes on a free list.
type Node struct {
Val int
Next *Node
}
type MyQueue struct {
In *Node
Out *Node
free *Node
}
func Constructor() MyQueue {
return MyQueue{
In: nil,
Out: nil,
}
}
func(this *MyQueue) Cycle() {
fmt.Println(">>>cycling in to out")
if this.In == nil {
// Nothing to cycle
fmt.Println(">>cycle empty in")
return
}
if this.Out != nil {
// Don't cycle yet
return
}
// Pop items off the in stack, push on the out stack
for {
current := this.In
this.In = this.In.Next // Pop In
fmt.Println("cycle>> pop in", current.Val)
current.Next = this.Out // Push Out
this.Out = current
current = this.In
if current == nil {
break
}
}
// Clear in stack
fmt.Println("cycle>> clear in")
this.In = nil
}
func (this *MyQueue) Push(x int) {
// Append to in stack. Leave there until we cycle.
n := &Node{
Val: x,
Next: this.In,
}
this.In = n
fmt.Println(">>push on in", x)
}
func (this *MyQueue) Pop() int {
if this.Empty() {
panic("popped empty stack")
}
if this.Out == nil {
this.Cycle()
}
value := this.Peek()
fmt.Println(">>pop Out")
this.Out = this.Out.Next
return value
}
func (this *MyQueue) Peek() int {
if this.Empty() {
panic("peek on empty stack")
}
this.Cycle()
fmt.Println("peek>>")
return this.Out.Val
}
func (this *MyQueue) Empty() bool {
fmt.Println("check for empty")
return this.In == nil && this.Out == nil
}
/**
* Your MyQueue object will be instantiated and called as such:
* obj := Constructor();
* obj.Push(x);
* param_2 := obj.Pop();
* param_3 := obj.Peek();
* param_4 := obj.Empty();
*/
Editorial note: other solutions submitted really stretch the definition of stack – a lot of them do do appends and slices, but of a single array, which is kind of not implementing two stacks at all.
Note 2: adding a free queue of nodes improves memory usage by 1%. Not worth it.
I started out with the simplest possible thing that could work: when looking to see if you have more than N of a thing, use a map.
**
* Definition for singly-linked list.
* type ListNode struct {
* Val int
* Next *ListNode
* }
*/
func hasCycle(head *ListNode) bool {
seen := make(map[*ListNode]bool)
for scan := head; scan != nil; scan = scan.Next{
_, ok := seen[scan]
if ok {
return true
}
seen[scan] = true
}
return false
}
Small, simple, but not very fast. 14th percentile in speed, 8th percentile in memory.
I vaguely remembered that there was a pointer-chasing way to do this, and that’s the fast and small way. (This falls into the “do you know the trick” category, which I kinda hate.)
func hasCycle(head *ListNode) bool {
slow := head
fast := slow
if head == nil {
return false
}
for {
// if we'd run off the end, stop.
if slow.Next == nil || fast.Next == nil || fast.Next.Next == nil {
return false
}
slow = slow.Next
fast = fast.Next.Next
if fast == slow {
return true
}
}
return false
}
Considerably faster: 95th percentile in speed, 45th in memory, which is interesting.
Now we start getting into “I would fire you if you did this” solutions.
How about if we just overwrite the value with an impossible one, and if we see the impossible value, return true (because it couldn’t be there unless we put it there)? It’s slower, which is to be expected, since we’re modifying the nodes and looking at them, not just looking at pointers. But surprisingly, the memory usage is still around 43%. And the list contents are trashed.
/**
* Definition for singly-linked list.
* type ListNode struct {
* Val int
* Next *ListNode
* }
*/
const invalidValue = 99999999
func hasCycle(head *ListNode) bool {
// Destructive version.
scan := head
if head == nil {
return false
}
for {
// if we'd run off the end, stop.
if scan.Next == nil {
return false
}
if scan.Val == invalidValue {
return true
}
scan.Val = invalidValue
scan = scan.Next
}
return false
}
So what gets us better memory usage? How about breaking the links, and pointing them to na-na land, and stopping if we get a pointer to na-na land?
/**
* Definition for singly-linked list.
* type ListNode struct {
* Val int
* Next *ListNode
* }
*/
func hasCycle(head *ListNode) bool {
// Another destructive version.
scan := head
// Create an off-in-nowhere node.
tumbolia := &ListNode{9999999, nil}
if head == nil {
return false
}
for {
if scan == tumbolia {
// we're in na-na land
return true
}
// if we'd run off the end, stop.
if scan.Next == nil {
return false
}
// point the next of this node to na-na land.
here := scan
scan = scan.Next
here.Next = tumbolia
}
return false
}
No major improvement. 90th percentile in speed, 43rd percentile in memory. List structure is trashed.
So overall, the Floyd two-pointer is the winner; would love to see something that uses less memory, but haven’t found anything yet.
I had a really hard time getting my head around this problem, which contributed to major flailing on my part trying to get it sorted. I had several almost-right solutions, but I kept not getting the recursion right. I eventually sorted it out to “I need to check the subtree heights” as the right attack, but didn’t finally sort it until the 10th try or so.
This wold absolutely have been a fail in an interview. I’m getting much better with pointers – I had no trouble getting the recursions to work, and never had a nil pointer problem – but I just could not get the concept clear enough in my head, and that lead to my just not getting it right in the code.
After a lot of flailing I finally came up with a height-checking algorithm that was the best shot at it I could do, but I had to finally check with the solutions to spot my error, which was treating the left and right subtrees separately when they needed to be unified.
Final version after the fix did okay in the rankings: top 84% in speed and top 81% in memory, but the path to getting it was really bad. I need to spend a lot more time on tree-crawling.
/**
* Definition for a binary tree node.
* type TreeNode struct {
* Val int
* Left *TreeNode
* Right *TreeNode
* }
*/
func isBalanced(root *TreeNode) bool {
if root == nil || (root.Left == nil && root.Right == nil) {
return true
}
_, which := heightCheck(root)
return which
}
func heightCheck(root *TreeNode) (int, bool) {
if root == nil {
return 0, true
}
lH, lB := heightCheck(root.Left)
rH, rB := heightCheck(root.Right)
// I was way overcomplicatng this, tracking the
// branches separately and not sending along a
// give-up flag. Doing that helped a lot.
if !lB || !rB || abs(lH - rH) > 1 {
return -1, false
}
return max(lH, rH) + 1, true
}
func abs(a int) int {
if a > 0 {
return a
}
return -a
}
func maxDepth(root *TreeNode) int {
if root == nil {
return 0
}
left := maxDepth(root.Left)
right := maxDepth(root.Right)
return max(left, right)+1
}
func max(a,b int) int {
if a>b {
return a
}
return b
}
Interestingly, if one adds a second recursion shortcut check for leaves, the memory usage gets much better: 99th percentile, but the execution time gets much worse: 54th percentile.
This is a tougher one, and honestly, you would have needed to have solved this yourself before to have gotten to a reasonable algorithm in the usual 1/2 hour time. It’s generally a significant sign if the problem description has to refer to Wikipedia for an accurate description of the problem.
This is one that is very simple to do by inspection, but difficult to do simply by algorithm, let alone an efficient one.
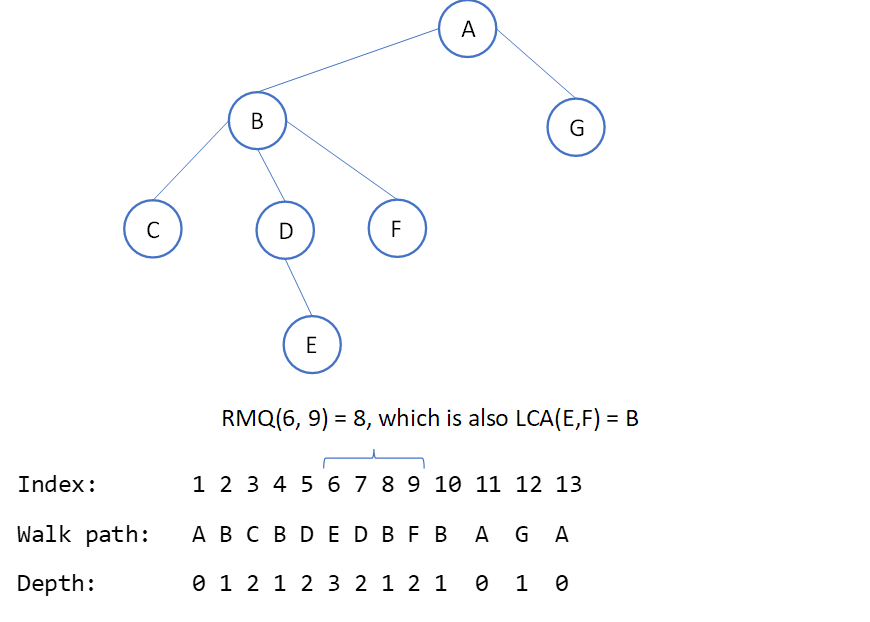
My first idea was that I’d need to know the paths to the nodes, and that I’d *handwave* figure out the common ancestor by using those. The good algorithm for this kind of uses the idea of paths to the nodes, but instead it does an in-order trace of the paths through the tree – an Euler tour, dude comes in everywhere – and that allows us to transform the problem into a range-minimum query (e.g., when I have node P and node q, and the path I needed to get from one to the other, at some point in there I’ll have a minimum-depth node, which will either be one of the two, or a third higher node).
The Wikipedia example shows this as an illustration:
To spell this out more explicitly: you can see we did the in-order tour, transforming the tree into a linear walk through it: A, down to B, down to C, back up to B, down to D, down to E, up to D, and so on. We record the node value and the depth at each step. To get the range query, we want the first appearance of each of two nodes we’re searching for (and we can record that as we’re crawling), and then to look for the highest node in the range of nodes including both of them. For the example in the diagram, step 6 is where we find the first node, E, and step 9 is where we find the second node, F. Iterating from step 6 to step 9, the node with the lowest depth in that range is B, and we can see from inspecting the tree that this is correct.
So.
At this point I’ve explained the solution, but have not written any code for it at all yet. Better go get that done.
Note: I’ve gotten the Euler crawl to mostly work, but I’m having trouble with the returned data from the crawl. Debugging…and yes, I am too cheap to pay for leetcode’s debugger. fmt.Println FTW.
The crawler crawls, but the output is wrong. I’ve tracked this down to a fundamental error on my part: Go arrays are not built for this kind of thing. I am switching the crawler over to building a linked list, which I think I only have to traverse one direction anyway, so it’s just as good.
This definitely was a failure to time-block. I will keep plugging on this until I actually finish solving it, but this would have been a DQ in an interview.
I’ve now discarded two different Euler crawls, and have a working one…but the range-minimum isn’t working as I expect it to. Will have to come back to it again. I begin to wonder if trying to track the start node is, in fact, a bad idea, and if I should simply convert the linked list I’m generating in the crawl to an array for the range minimum once it’s returned.
The crawl now returns the head and tail of a list that contains the visit order for the Euler crawl: node, left subtree in order, node again, right subtree in order, node again. This breaks down like this:
If the current head is nil, return [nil, nil].
Generate a crawl node for just this node at the current level
Set head and tail to this node
If the current head points to a leaf node:
Return head and tail.
Otherwise:
Crawl the left side at level+1, getting a leftside head and tail.
Crawl the right side at level+1, getting a rightside head and tail.
If the leftside crawl is non-null:
Set tail.next to leftside head.
Create a new crawl node for the current node at the current level.
Set leftside tail node's next to this new node.
Set tail to this middle node.
If the rightside crawl is non-null:
Set tail.next to the rightside head.
Create a new crawl node for the current node at the current level.
Set rightside tail node's next to this new node.
Set tail to this new node.
Return head and tail.
This returns a singly-linked list with an in-order traversal, recording every node visited and the tree level at which it was seen. We should now be able to find the start and end nodes, and scan the list between the two inclusive, looking for the highest node, and that should find the LCA.
The scan is a bit of a bastard as well. The nodes may appear in any order, and we have to find the start and end no matter which order they show up in. I initially tried swapping them if they were out of order, but this didn’t work as I expected – that may have been other bugs, but I coded around it in the final scan code.
The final scan first says “I don’t have either node” and skips nodes until it finds one of them. Once it does, it starts looking for the node with the highest level. The tricky bit is that we need to detect that we’ve found the first node, then start checking, and only stop checking after we find the end node (as it may be the highest, since nodes are considered their own roots).
Here’s the final code. It did not do well in the rankings: bottom 5% in speed, and bottom 25% in memory usage. I suspect I could improve it by merging the “find the local high node” code into the Euler crawl, and by not actually recording the nodes in the linked list at all but passing the state around in the recursion.
Lessons learned:
Do not try to do complicated array machinations in Go. Better to record the data in a linked list if you’re doing something that needs to recursively append sublists.
Think more clearly about recursion. What is the null case? What is the one-element case? What is the more-than-once case? What is the termination criterion for the more-than-one case?
Don’t be afraid to discard an old try and do something different. Comment out the failed code (and note to the interviewer that you’d check the broken one in on a local branch in case you wanted to go back to it).
Continuing to practice with Go pointer code is necessary. I’m a bit weak with pointers.
This took way too long to do, and way too many shots at getting to something that would work at all. I grade myself a fail on this one. I might come back at a later date and try to make it faster and smaller.
Addendum: removed the debugging and the dump of the crawl output. Even without doing anything else, that bumped my stats to the top 73% in runtime and top 99% in memory usage, and that is a pass with flying colors!
/**
* Definition for a binary tree node.
* type TreeNode struct {
* Val int
* Left *TreeNode
* Right *TreeNode
* }
*/
type eulerNode struct {
node *TreeNode
depth int
next *eulerNode
}
func lowestCommonAncestor(root, p, q *TreeNode) *TreeNode {
// Use the transformation of this problem into a range-minimum one.
// Crawl the tree in-order, creating an Euler path. Each step records
// the node value and the depth.
head, tail := eulerCrawl2(root, p, q, 0)
// dump crawl output - note that removing this should make the code
// significantly faster
scan := head
for {
if scan == nil {
break
}
fmt.Println(scan.node.Val, "depth", scan.depth)
scan = scan.next
}
fmt.Println("crawl complete", head, tail)
// Start is the beginning of the range, and the end of the path is the end.
// Find the path minimum in the range (the lowest depth value).
var ancestor *TreeNode
minDepth := 9999999999
fmt.Println("Start at", head.node.Val, head.depth)
foundP := false
foundQ := false
for scan := head; scan != nil; scan = scan.next {
fmt.Println("node", scan.node.Val, scan.depth)
if scan.node.Val == p.Val {
fmt.Println("found p")
foundP = true
}
if scan.node.Val == q.Val {
fmt.Println("found q")
foundQ = true
}
if !foundP && !foundQ {
fmt.Println("skip", scan.node.Val)
continue
}
fmt.Println("check", scan.node.Val, scan.depth)
if scan.depth < minDepth {
// New range minimum
minDepth = scan.depth
ancestor = scan.node
fmt.Println("new candidate min at", scan.node.Val, scan.depth)
}
if foundP && foundQ {
fmt.Println("found and processed complete range")
break
}
}
fmt.Println("ancestor is", ancestor.Val)
return ancestor
}
func eulerCrawl2(root, p, q *TreeNode, depth int) (*eulerNode, *eulerNode) {
// Nil tree returns nil pointer
if root == nil {
fmt.Println("skipping nil pointer")
return nil, nil
}
// Non-nil next node. Generate a crawl node for this tree node.
fmt.Println("adding crawl node for", root.Val)
head := &eulerNode{
node: root,
next: nil,
depth: depth,
}
tail := head
// If this is a leaf, the crawl of
// this node is just this node. Head and tal point to the same node.
if root.Left == nil && root.Right == nil {
fmt.Println("returning at leaf")
return head, tail
}
// Non-leaf. Crawl will be this node, the left subtree at depth+1,
// another copy of this node at this depth, the right subtree at depth+1,
// and one more copy of this node.
fmt.Println("crawling down")
leftSubtreeHead, leftSubtreeTail :=
eulerCrawl2(root.Left, p, q, depth+1)
rightSubtreeHead, rightSubtreeTail :=
eulerCrawl2(root.Right, p, q, depth+1)
// Chain the results together:
// - this tree node
// - the left crawl below it
// - another copy of this node
// - the right crawl below it
// - a final copy of this node
// Link this node to the start of the list from the left crawl
if leftSubtreeHead != nil {
// If there is a crawl below, link it in, and add another
// copy of the current node for coming back up
tail.next = leftSubtreeHead
leftSubtreeTail.next = &eulerNode{
node: root,
next: nil,
depth: depth,
}
tail = leftSubtreeTail.next
}
if rightSubtreeHead != nil {
// right crawl exists. Add it at the current tail, reset tail.
tail.next = rightSubtreeHead
rightSubtreeTail.next = &eulerNode{
node: root,
next: nil,
depth: depth,
}
// reset tail to new last node
tail = rightSubtreeTail.next
}
// Return head and tail of the newly-generated list of crawled
// nodes.
fmt.Println("returning results at depth", depth)
return head, // Head of this new list
tail // Tail of this new list
}