I had a really hard time getting my head around this problem, which contributed to major flailing on my part trying to get it sorted. I had several almost-right solutions, but I kept not getting the recursion right. I eventually sorted it out to “I need to check the subtree heights” as the right attack, but didn’t finally sort it until the 10th try or so.
This wold absolutely have been a fail in an interview. I’m getting much better with pointers – I had no trouble getting the recursions to work, and never had a nil pointer problem – but I just could not get the concept clear enough in my head, and that lead to my just not getting it right in the code.
After a lot of flailing I finally came up with a height-checking algorithm that was the best shot at it I could do, but I had to finally check with the solutions to spot my error, which was treating the left and right subtrees separately when they needed to be unified.
Final version after the fix did okay in the rankings: top 84% in speed and top 81% in memory, but the path to getting it was really bad. I need to spend a lot more time on tree-crawling.
/**
* Definition for a binary tree node.
* type TreeNode struct {
* Val int
* Left *TreeNode
* Right *TreeNode
* }
*/
func isBalanced(root *TreeNode) bool {
if root == nil || (root.Left == nil && root.Right == nil) {
return true
}
_, which := heightCheck(root)
return which
}
func heightCheck(root *TreeNode) (int, bool) {
if root == nil {
return 0, true
}
lH, lB := heightCheck(root.Left)
rH, rB := heightCheck(root.Right)
// I was way overcomplicatng this, tracking the
// branches separately and not sending along a
// give-up flag. Doing that helped a lot.
if !lB || !rB || abs(lH - rH) > 1 {
return -1, false
}
return max(lH, rH) + 1, true
}
func abs(a int) int {
if a > 0 {
return a
}
return -a
}
func maxDepth(root *TreeNode) int {
if root == nil {
return 0
}
left := maxDepth(root.Left)
right := maxDepth(root.Right)
return max(left, right)+1
}
func max(a,b int) int {
if a>b {
return a
}
return b
}
Interestingly, if one adds a second recursion shortcut check for leaves, the memory usage gets much better: 99th percentile, but the execution time gets much worse: 54th percentile.
First, shout-out to ShineX Media for setting me on the right track for this.
If you use modern versions of Photoshop, you’ve probably noticed that in the “New file…” dialog, there’s a “Recent” tab, which is the default one that comes up. If you’ve been using it to create files in different shapes and sizes and formats, you’ll notice that it gets pretty cluttered up, and it’s easy to accidentally, say, pick something with the right dimensions but wrong DPI and then waste a chunk of time working on an unusable document.
Adobe has provided no built-in way to clear this. People have been asking since 2016 for a solution.
The one documented on the Adobe site, go to the preferences and turn this version of the dialog off, is like the old joke:
“Doctor, my shoulder hurts when I raise my hand above waist level.”
“Well…don’t do that.”
I mean, it’s a solution; it’s just not a very reasonable one.
I spent a fair amount of time googling around and finally found a reference to Shine X Media’s video that explains how to do it for Windows; essentially you close Photoshop (very important to keep PS from just rewriting the file again), go looking through the AppData directory for a file named MRU New Doc Sizes (MRU is Most Recently Used), and remove it.
On the Mac, this lives in "${HOME}/Library/Preferences/Adobe Photoshop 2024 Settings/MRU New Doc Sizes.json", and you can simply use the Go… option in the Finder to navigate to the Adobe Photoshop 2024 Settings directory and drag it to the trash.
Again, make sure Photoshop is not running!
This is confirmed to work fine on my 2024 install under Sonoma. Happy and clean open dialogs to you!
This is a tougher one, and honestly, you would have needed to have solved this yourself before to have gotten to a reasonable algorithm in the usual 1/2 hour time. It’s generally a significant sign if the problem description has to refer to Wikipedia for an accurate description of the problem.
This is one that is very simple to do by inspection, but difficult to do simply by algorithm, let alone an efficient one.
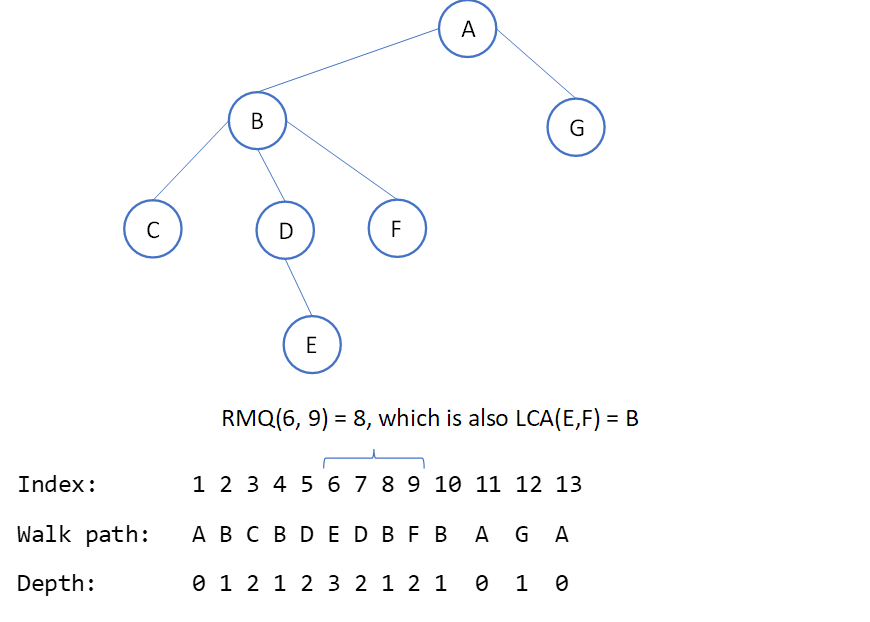
My first idea was that I’d need to know the paths to the nodes, and that I’d *handwave* figure out the common ancestor by using those. The good algorithm for this kind of uses the idea of paths to the nodes, but instead it does an in-order trace of the paths through the tree – an Euler tour, dude comes in everywhere – and that allows us to transform the problem into a range-minimum query (e.g., when I have node P and node q, and the path I needed to get from one to the other, at some point in there I’ll have a minimum-depth node, which will either be one of the two, or a third higher node).
The Wikipedia example shows this as an illustration:
To spell this out more explicitly: you can see we did the in-order tour, transforming the tree into a linear walk through it: A, down to B, down to C, back up to B, down to D, down to E, up to D, and so on. We record the node value and the depth at each step. To get the range query, we want the first appearance of each of two nodes we’re searching for (and we can record that as we’re crawling), and then to look for the highest node in the range of nodes including both of them. For the example in the diagram, step 6 is where we find the first node, E, and step 9 is where we find the second node, F. Iterating from step 6 to step 9, the node with the lowest depth in that range is B, and we can see from inspecting the tree that this is correct.
So.
At this point I’ve explained the solution, but have not written any code for it at all yet. Better go get that done.
Note: I’ve gotten the Euler crawl to mostly work, but I’m having trouble with the returned data from the crawl. Debugging…and yes, I am too cheap to pay for leetcode’s debugger. fmt.Println FTW.
The crawler crawls, but the output is wrong. I’ve tracked this down to a fundamental error on my part: Go arrays are not built for this kind of thing. I am switching the crawler over to building a linked list, which I think I only have to traverse one direction anyway, so it’s just as good.
This definitely was a failure to time-block. I will keep plugging on this until I actually finish solving it, but this would have been a DQ in an interview.
I’ve now discarded two different Euler crawls, and have a working one…but the range-minimum isn’t working as I expect it to. Will have to come back to it again. I begin to wonder if trying to track the start node is, in fact, a bad idea, and if I should simply convert the linked list I’m generating in the crawl to an array for the range minimum once it’s returned.
The crawl now returns the head and tail of a list that contains the visit order for the Euler crawl: node, left subtree in order, node again, right subtree in order, node again. This breaks down like this:
If the current head is nil, return [nil, nil].
Generate a crawl node for just this node at the current level
Set head and tail to this node
If the current head points to a leaf node:
Return head and tail.
Otherwise:
Crawl the left side at level+1, getting a leftside head and tail.
Crawl the right side at level+1, getting a rightside head and tail.
If the leftside crawl is non-null:
Set tail.next to leftside head.
Create a new crawl node for the current node at the current level.
Set leftside tail node's next to this new node.
Set tail to this middle node.
If the rightside crawl is non-null:
Set tail.next to the rightside head.
Create a new crawl node for the current node at the current level.
Set rightside tail node's next to this new node.
Set tail to this new node.
Return head and tail.
This returns a singly-linked list with an in-order traversal, recording every node visited and the tree level at which it was seen. We should now be able to find the start and end nodes, and scan the list between the two inclusive, looking for the highest node, and that should find the LCA.
The scan is a bit of a bastard as well. The nodes may appear in any order, and we have to find the start and end no matter which order they show up in. I initially tried swapping them if they were out of order, but this didn’t work as I expected – that may have been other bugs, but I coded around it in the final scan code.
The final scan first says “I don’t have either node” and skips nodes until it finds one of them. Once it does, it starts looking for the node with the highest level. The tricky bit is that we need to detect that we’ve found the first node, then start checking, and only stop checking after we find the end node (as it may be the highest, since nodes are considered their own roots).
Here’s the final code. It did not do well in the rankings: bottom 5% in speed, and bottom 25% in memory usage. I suspect I could improve it by merging the “find the local high node” code into the Euler crawl, and by not actually recording the nodes in the linked list at all but passing the state around in the recursion.
Lessons learned:
Do not try to do complicated array machinations in Go. Better to record the data in a linked list if you’re doing something that needs to recursively append sublists.
Think more clearly about recursion. What is the null case? What is the one-element case? What is the more-than-once case? What is the termination criterion for the more-than-one case?
Don’t be afraid to discard an old try and do something different. Comment out the failed code (and note to the interviewer that you’d check the broken one in on a local branch in case you wanted to go back to it).
Continuing to practice with Go pointer code is necessary. I’m a bit weak with pointers.
This took way too long to do, and way too many shots at getting to something that would work at all. I grade myself a fail on this one. I might come back at a later date and try to make it faster and smaller.
Addendum: removed the debugging and the dump of the crawl output. Even without doing anything else, that bumped my stats to the top 73% in runtime and top 99% in memory usage, and that is a pass with flying colors!
/**
* Definition for a binary tree node.
* type TreeNode struct {
* Val int
* Left *TreeNode
* Right *TreeNode
* }
*/
type eulerNode struct {
node *TreeNode
depth int
next *eulerNode
}
func lowestCommonAncestor(root, p, q *TreeNode) *TreeNode {
// Use the transformation of this problem into a range-minimum one.
// Crawl the tree in-order, creating an Euler path. Each step records
// the node value and the depth.
head, tail := eulerCrawl2(root, p, q, 0)
// dump crawl output - note that removing this should make the code
// significantly faster
scan := head
for {
if scan == nil {
break
}
fmt.Println(scan.node.Val, "depth", scan.depth)
scan = scan.next
}
fmt.Println("crawl complete", head, tail)
// Start is the beginning of the range, and the end of the path is the end.
// Find the path minimum in the range (the lowest depth value).
var ancestor *TreeNode
minDepth := 9999999999
fmt.Println("Start at", head.node.Val, head.depth)
foundP := false
foundQ := false
for scan := head; scan != nil; scan = scan.next {
fmt.Println("node", scan.node.Val, scan.depth)
if scan.node.Val == p.Val {
fmt.Println("found p")
foundP = true
}
if scan.node.Val == q.Val {
fmt.Println("found q")
foundQ = true
}
if !foundP && !foundQ {
fmt.Println("skip", scan.node.Val)
continue
}
fmt.Println("check", scan.node.Val, scan.depth)
if scan.depth < minDepth {
// New range minimum
minDepth = scan.depth
ancestor = scan.node
fmt.Println("new candidate min at", scan.node.Val, scan.depth)
}
if foundP && foundQ {
fmt.Println("found and processed complete range")
break
}
}
fmt.Println("ancestor is", ancestor.Val)
return ancestor
}
func eulerCrawl2(root, p, q *TreeNode, depth int) (*eulerNode, *eulerNode) {
// Nil tree returns nil pointer
if root == nil {
fmt.Println("skipping nil pointer")
return nil, nil
}
// Non-nil next node. Generate a crawl node for this tree node.
fmt.Println("adding crawl node for", root.Val)
head := &eulerNode{
node: root,
next: nil,
depth: depth,
}
tail := head
// If this is a leaf, the crawl of
// this node is just this node. Head and tal point to the same node.
if root.Left == nil && root.Right == nil {
fmt.Println("returning at leaf")
return head, tail
}
// Non-leaf. Crawl will be this node, the left subtree at depth+1,
// another copy of this node at this depth, the right subtree at depth+1,
// and one more copy of this node.
fmt.Println("crawling down")
leftSubtreeHead, leftSubtreeTail :=
eulerCrawl2(root.Left, p, q, depth+1)
rightSubtreeHead, rightSubtreeTail :=
eulerCrawl2(root.Right, p, q, depth+1)
// Chain the results together:
// - this tree node
// - the left crawl below it
// - another copy of this node
// - the right crawl below it
// - a final copy of this node
// Link this node to the start of the list from the left crawl
if leftSubtreeHead != nil {
// If there is a crawl below, link it in, and add another
// copy of the current node for coming back up
tail.next = leftSubtreeHead
leftSubtreeTail.next = &eulerNode{
node: root,
next: nil,
depth: depth,
}
tail = leftSubtreeTail.next
}
if rightSubtreeHead != nil {
// right crawl exists. Add it at the current tail, reset tail.
tail.next = rightSubtreeHead
rightSubtreeTail.next = &eulerNode{
node: root,
next: nil,
depth: depth,
}
// reset tail to new last node
tail = rightSubtreeTail.next
}
// Return head and tail of the newly-generated list of crawled
// nodes.
fmt.Println("returning results at depth", depth)
return head, // Head of this new list
tail // Tail of this new list
}
A bit of a break working on a friend’s art business launch; still working on that, but made some time to come back to leetcode month today.
Today’s problem is flood fill; another easy-rated one. This is again a recursion problem, and the tricky bit is as usual preventing extra recursion that doesn’t need to happen.
Doing this one is made a lot easier by unifying the calling sequence with a helper function that adds an
Go-specific issues for me were properly extracting the dimensions of a two-D array and having to do that with a pointer. Since we want to alter the array we’re flood filling, we need to pass a pointer to it so that we can actually modify the source array.
I got tripped up by the termination condition. In addition to “are we outside the bounds of the array”, we also need to check if this cell needs filling at all (is it the fill color already? Is it the color we want to fill?).
I did need a couple runs with debug prints in to spot where my recursion was going wrong; the first cut didn’t have the “is this already the right color” test, and I was able to catch that one with the supplied test cases. It. failed on the submit because I wasn’t checking for “is the fill already done” case.
How did I do relative to other cases? Pretty good! Runtime in the top 92%, memory usage a quarter of a percent short of the 100th percentile. Should be a pass in an interview. (I did get this one at Thumbtack, and came out with a solution similar to this one, except I used an 8-cell neighborhood when a 4-cell will work. Too many Game-of-Life programs.)
Should have been an easy one, but I haven’t written one by hand in years. Ended up Googling.
Some interesting notes on the code:
for with a conditional break inside is considerably slower than for condition.
The version of this that I learned back when used a step division, and that actually is much harder to get right. The upper/lower/mid version is much easier to get right.
I decided to not do a recursive solution this time on purpose. The expressivity that recursion gives you is not to be denied.
Final version scored well: 90% on speed, 97% on memory. Acceptable, but the amount of dicking around was not. Note: study up more of these common but not commonly coded algorithms.
func search(nums []int, target int) int {
// Find midpoint, check element; equal, less, or greater.
// if the step size goes to 0 we did not find.
low := 0
high := len(nums) -1
for low <= high {
mid := (high + low )/ 2
if nums[mid] < target {
low = mid + 1
} else if nums[mid] > target {
high = mid -1
} else {
return mid
}
}
return -1
}
Problem: two strings. Are they anagrams of each other?
Software engineer hat again: if these are arbitrary Unicode strings, then the right solution is count the characters in the first string, binning the counts by character, and then subtract the counts of the characters in the second string. If the characters are ASCII, then you can be clever and use the character value as an index into an array and do the same add/subtract algorithm…but someone will use a non-ASCII character, sooner or later. And the failure mode of clever is…well.
Score: bottom 15% in time and space, but I’ll take that for the vastly reduced need to worry about weird input. If we remove the conversion to string and use bytes, then it improves to 30%. The real win doesn’t happen until the conversion to arrays. I initially had a delete to remove counts that went to 0 and a check for counts that went negative (chars in t not in s) but there wasn’t a significant speedup.
func isAnagram(s string, t string) bool {
// easiest way is to map the character counts into a hash.
// if the two strings match, there should be no odd counts.
if len(s) != len(t) {
return false
}
charCounts := make(map[byte]int)
for i := range(s) {
charCounts[s[i]]++
}
for i := range(t) {
x := string(t[i])
charCounts[x]--
}
for _, count := range(charCounts) {
if count != 0 {
return false
}
}
return true
}
Giving up and using an array of 256 ints, indexed by the int value of the bytes, it’s much faster: 93% on time, 98% on space. Good enough. I suppose you could use this on Unicode input, since it’s just looking at raw bytes. Depends on whether you have a character that can be represented in more than one way in Unicode.
The syntax for creating arrays continues to be a problem. I’m going to standardize on assigning the type followed by {} to the variable.
I chose the “busy software engineer” approach: I know an algorithm that will work and is trivial to implement. Implement that.
To remind everyone what inverting a tree is: if criterion for insertion is left branch < right, then then output tree should have left branch > right. The dead simple algorithm is top-down: save the left, assign the right to the left, assign the saved to the right, recurse.
It’s clear, it’s simple, and fast to code. I literally had a working solution in 2 runs (forgot the null root case on the first run).
/**
* Definition for a binary tree node.
* type TreeNode struct {
* Val int
* Left *TreeNode
* Right *TreeNode
* }
*/
func invertTree(root *TreeNode) *TreeNode {
if root == nil {
return nil
}
invertTree(root.Left)
invertTree(root.Right)
t := root.Left
root.Left = root.Right
root.Right = t
return root
}
About as simple as you can possibly get. Scorewise, it’s fast: top 77%. Memorywise, it’s pretty poor: bottom 8%.
I’m betting a pointer crawl would use less memory but wouldn’t necessarily be that much faster. Let’s see.
First note, still writing append as if this were Scala. Sigh.
This try ends up in an infinite loop; I’m mismanaging the stack somehow. (See why letting Go do it is better?) I’m declaring this good enough and moving on. I expect I could write a version where I manage the stack myself, but this is why we invented higher-level languages.
Unless our trees are always incredibly deep, this is the right way to do this. Even skipping the recursion for nil subtrees doesn’t really make it faster.
On the other hand, I solved the initial recursive version in about 5 minutes, so I’m getting my feet back under me.
I’m perceiving a pattern in my failures here and it is 100% “did you absolutely understand the requirements”.
Detecting a palindromic string was the easy part: just put an index at the end and the beginning, and march them toward the middle. If they meet or pass each other, then we succeeded. If at any point the characters at the indexes don’t match, we fail.
The problematic part was the cleanup of the initial string. Lowercasing wasn’t bad, though I had to look up where the function lived (it’s strings.ToLower()). Filtering the input was harder. I had to go check Stack Overflow and found this code, which is very nice and will go in my personal toolbox:
The strings.Map function is really nice for “do something for every rune in a string”, especially since the special -1 return value says “drop this character”. Can do just about any transliteration you want with that! The unicode.IsDigit function highlights my “you did not read the instructions” error: I assumed that it would be alpha only, and that was incorrect; it was alphanumeric input.
I did spot a useful optimization: if the string is less than two characters long, by definition it’s a palindrome, so we can skip scanning it altogether.
Otherwise the algorithm I coded to scan was right the first time.
How’d I do comparatively? Meh. Runtime in the bottom 50%, memory in the top 60%. I think the lowercase followed by the cleanup is the culprit, and doing it all in one loop would be faster. I don’t think it’s as clear.
I tried a couple variations, and all of them are worse:
Reverse the string and compare it to itself
Inline the cleanup
This just may be something that Go kind of sucks at doing.
func isPalindrome(s string) bool {
// lowercase, skim out all non-alpha characters
s = strings.ToLower(s)
s = spaceMap(s)
if len(s) < 2 {
return true
}
begin := 0
end := len(s) - 1
for {
if begin > end {
return true
}
if begin == end {
return true
}
if s[begin] != s[end] {
return false
}
begin++
end--
}
}
func spaceMap(str string) string {
return strings.Map(func(r rune) rune {
if !unicode.IsDigit(r) && !unicode.IsLetter(r) {
return -1
}
return r
}, str)
}
You’re given an ordered array of prices, and are asked to find the maximum inter-day profit. Constraints: the buy must be before the sell (first price array index < second price array index), and profit is 0 if there is no positive delta.
I originally did a brute force solution that essentially came down to a double loop. Worked fine for small examples, but failed on time for long ones.
So I went and took a shower, and got half of it: if I find the minimum value, then no price after that can possibly have a bigger delta. However, it’s possible that there was a bigger delta preceding that, and I got stuck there for a while, wondering about iterating backward, but couldn’t see a definite siimple algorithm.
I got a hint that I could use a sliding window, and that gave me the right solution.
Start at index 0 as the tentative minimum.
Walk a second index forward.
If the walking index finds a new minimum, move the minimum pointer.
Otherwise, calculate the delta between the current minimum and the walking index price.
If the delta is > the old max delta, save it.
My original insight would eliminate whatever part of the array that followed the global minimum, but would have missed possible local maximum deltas (e.g., [10, 100, 1, 5] would have a true max delta of 90; scanning only after the global minimum would only have found a delta of 4). The sliding window finds that first delta of 90, and then keeps it, even though we find a new minimum at 1.
func maxProfit(prices []int) int {
// iterate over the array from the start.
// take the current item as the start price.
// find the max price after this one that leads to a profit, or 0.
// repeat for each day up to the last-1.
// if the profit for a given iteration is > the current, save it instead.
maxProfit := 0
tentativeMinIndex := 0
for i := tentativeMinIndex; i < len(prices); i++ {
if prices[i] < prices[tentativeMinIndex] {
tentativeMinIndex = i
continue
}
// haven't moved minimum, calc profit
thisProfit := prices[i] - prices[tentativeMinIndex]
if thisProfit > maxProfit {
maxProfit = thisProfit
}
}
return maxProfit
}
How’d I do? Bad on the initial O(N^2) iteration, but fab on the sliding window version: top 99% in speed, top 93% in memory.
Taking a shower helped, but I won’t be able to do that in an interview, alas. (Another good argument for working at home.)
Next is palindromes, and we’ll be back to fun with Go strings again.
Today’s challenge is Valid parens. And it reminded me of several of the things that I don’t particularly like in Go.
Problem statement boils down to “here’s a string of brackets: parens, square brackets, braces. Tell us if they match properly (true) or don’t (false)”. Algorthmically this is dead simple:
Start with an empty stack.
for each character in the string:
if it's an open bracket, push it.
if its a close bracket:
if the stack is empty, return false.
if the top of the stack isn't the matching open, return false.
pop the stack.
When we're done, return true if the stack is empty, false otherwise.
In Perl or Python, I’d have a stack pointer, and move it up and down an array as I pushed and popped characters by altering the stack pointer and assigning to the appropriate point in the array. If the stack pointer went below 0, I’ve gotten too many close parens, and I return false.
This approach doesn’t work well at all with Go, because Go arrays and slices Do Not Work Like That.
To push onto an existing array, we need to use a := append(a, new). Just assigning to an index outside of the slice’s current boundaries will panic.
We could still use the stack pointer to move backward, but then we’d have to have more complex code to decide if we need to append or just move the pointer. (Side note: doing it that way would probably use less memory — the working version of my solution used more memory than 90% of the other solutions). Instead, we just use the slice notation to pop the stack instead, with a := a[:len(a)-1].
My original iterations with a real stack pointer failed miserably because I wasn’t properly tracking the length of the array, and was perpetually getting the stack pointer position wrong, causing the code to panic. It was only after completely discarding the stack pointer that I got it to finally work.
Items of note:
I remembered I’d need to use range() to iterate over the string, but forgot that I would have to string() the characters I was getting so they were strings instead of runes. I wasted a good chunk of time trying to mess with runes before I realized that I needed string() instead. Runes are considerably more second-class citizens.
Still running afoul of using make() properly. Finally figured out the syntax to create an empty string array, but it took some Googling to get it.
I decided to make the code less complex by creating a pairs map that mapped left brackets to right ones. This meant I could check pairs[left] == right for whether I’d matched the left and right brackets. It also meant that if we ever added more bracket pairs in the future, it’d be be easier to implement them.
I got fenceposted by a[len(a)-1] accessing the last element, and a[:len([a)-1]dropping the last element. I naively expected that since a[len(a)-1] accessed the last element, I’d want a[:len(a)-2] to drop that last element, but that takes one too many, running me into another fencepost. Yes, it’s good that it’s symmetric, and now I’ll remember, but I definitely had to look it up to figure out both of them.
Forgot the check for “did we close all the opens”. I probably would not have missed it if I was making my own test cases, but it wasn’t in the tests. Note to self: watch out for poor initial test cases. There is an opportunity to add more, I think?
So how’d I do overall? We saw I was in the bottom 10% in memory usage, boo, but runtime? “Beats 100.00% of users with Go”.
I’ll definitely take that as a win, but it’s definitely obvious I need to keep practicing and getting these idioms back under my belt.
func isValid(s string) bool {
// We'll run through the string, doing the following:
// - if we see an open bracket, we stack it.
// - if we see a close bracket, we pop the stack. If the
// brackets match, we continue, otherwise we fail.
// - when we run out of brackets, the stack must be empty or we fail.
stack := make([]string,0)
pairs := map[string]string{
"(": ")",
"[": "]",
"{": "}",
}
for i := range s {
char := string(s[i])
_, ok := pairs[char]
if ok {
// left, push it
stack = append(stack, char)
} else {
// right, stack empty?
if (len(stack) == 0) {
fmt.Println("pop of empty stack")
return false
}
// Not empty. match?
if (pairs[stack[len(stack)-1]] != char) {
fmt.Println ("mismatch")
// mismatched bracket, fail
return false
}
// Match. Pop stack.
stack = stack[:len(stack)-1]
}
}
// Check for "did we close all the open brackets".
return len(stack) == 0
}
That’s one for today, and I need to clean the house, so I’ll call it a day.