[It seems like a good idea to lay out some history of this project and its goals, so I’m posting this before today’s progress update.]
WebWebXNG Overview
We’ve been concentrating on the nuts and bolts of the conversion, but maybe we should step back and look at the project as a whole, so we can get some perspective on where it started, where we are, and where we might go from here.
“Ed’s Whiteboard” and Wikis
Around 1997, we had just recently converted to Unix machines from IBM mainframes at the Goddard Space Flight Center, where I was then working as a contractor on a relatively large Perl project. Collaboration tooling was severely lacking. Bug trackers were very difficult to install or very expensive.
Our process was mostly email, and one actual physical whiteboard in our project lead’s office had become the definitive source of truth where everything was recorded. There were numerous DO NOT ERASE signs on the door, on the whiteboard, next to it…it was definitely a single point of failure for the project, and it literally required you to go walk over to Ed’s office to get the project status, or to take notes on paper and transfer them to one’s own whiteboard/files/etc. If you needed to know something about the project, “Ed’s whiteboard” was where you found it.
Our process was weekly status meeting, we agree on who’s doing what, Ed – and only Ed! – writes it on his whiteboard, and as the week goes on we mail him with our updates, which he’d then transfer to the board. It did give us a running status, a list of bugs, and assignments, but it was clear that we needed something better, more flexible, and less fragile than something that could be destroyed by an accidental brush up against it or a well-meaning maintenance person.
Bettering the whiteboard
It was about this time that I stumbled on the original c2.com WikiWiki. The idea that a website could be implemented in such a way that it could extend itself was a revelation. (Most websites were pretty simple-minded in 1997; you’d code up a bunch of HTML by hand and deploy it to your web server, and that was it.) It took a few days for the penny to drop, but I realized that, hey, we could move Ed’s whiteboard to a website! Instead of writing things on a physical whiteboard and worrying that it might get erased, we could record everything on a virtual one, share it among all the team members, and have historical backups of the project state.
We could discuss things in sort-of real time and have a record of the conversation to refer to later, and link the discussion to a bug, or a feature request, or…
We could track bugs on one page, assignments on another, have room to discuss implementation, record the minutes of our status meetings, and just generally document things we needed to share amongst ourselves. It was Ed’s whiteboard plus, and best of all, we could do it for free!
We did have a few extra requirements. The biggest one was that we needed to be able to provide different levels of access to accessing and editing the site, depending on who you were. After some searching around, I found David McNicol’s WebWeb.
WebWeb and its evolution to WebWebX
WebWebX started off as an extended version of WebWeb, a derivative of Ward Cunningham’s original WikWIki, written by David McNicol at the University of Strathcyled . WebWeb was a monolithic CGI script that added a few extra features to the original WikiWiki codebase, most notably access levels, which we needed more than anything else. We wanted to have some pages publicly readable, but only writable by project members, and some project tracking available for read by a subset of users and editable only by a yet smaller subset — the dev team.
WebWeb did have some limitations that made it not quite good enough out of the box. The biggest issue was the original data storage, which used Storable and Perl DBM files; pages were “frozen” with Storable, making them into strings. They were then stored in the DBM file under a key composed of the page name and a version number; this made operations like history, removing old versions, searching, etc. all relatively easy, since a DBM file looked like a hash to the Perl code.
The biggest problem with this was that the size of a page was limited by the per-item storage capacity of the underlying DBM implementation, meaning that a page that got “too big” suddenly couldn’t be saved any more. This was a real usability issue, as it was very difficult to predict when you’d exceed the allowable page size — and worse, different Perl implementations on different machines might have radically different limitations on the allowable page size.
I undertook a rewrite of WebWeb to make it more modular, easier to maintain, and more performant, most specifically focusing on the page size issue. It was clear that we’d need to fix that problem, but most of the rest of WebWeb was fine as it was.
RCS and PageArchive
I started out by “factoring out” (not really, because there was no test suite!) the DBM code into a separate class which I dubbed PageArchive, creating an interface to the page management code as a separate class. A reasonable choice to allow me to change the underlying implementation; I’d learned enough OO programming to have the idea of a Liskov substitution, but none of us really had internalized the idea that writing a test suite for a module was a good idea yet.
This complexified the mainline code a bit, as accessing the pages needed to use function calls instead of hash accesses, but it wasn’t too bad — the overall size of the project was fairly small, and the vast majority of the lines of code was inlined HTML heredocs.
With the page storage code isolated in PageArchive, I could start replacing the mechanism it used for storage. One of the other tools we’d recently started using was RCS to do source code management, mostly because it was easy to start using and it was free with the operating system. We might have been able to use CVS, but it would have required a lot more coordination with our system administrator; with RCS, we just had to decide to start using it.
From 25 years later, RCS looks hideously primitive. Each file is individually versioned, with a hidden file next to it containing the deltas for each version. For our code, even though it helped us a lot on a day-to-day basis, it made release management very difficult— a code freeze had to be imposed, and a tar file built up out of the frozen codebase. This then had to be deployed to a separate machine and manually tested against a list of features and bugs to ensure that we had a clean release. This all fell on the shoulders of our release manager, who was, fortunately for us, very meticulous! Not something that would work nowadays, but for 1997, it was a huge improvement.
For storing pages in a wiki, on the other hand, RCS was great. We really were more interested in maintaining the history of each individual page rather than of the wiki as a whole anyway, so RCS perfectly reasonable for this. I updated PageArchive to use RCS versioning to store stringified versions of the pages instead of storing them in DBM. Because I’d already abstracted the operations on the pages, it was easy to swap out one implementation for another. Pages could now be whatever size we wanted!
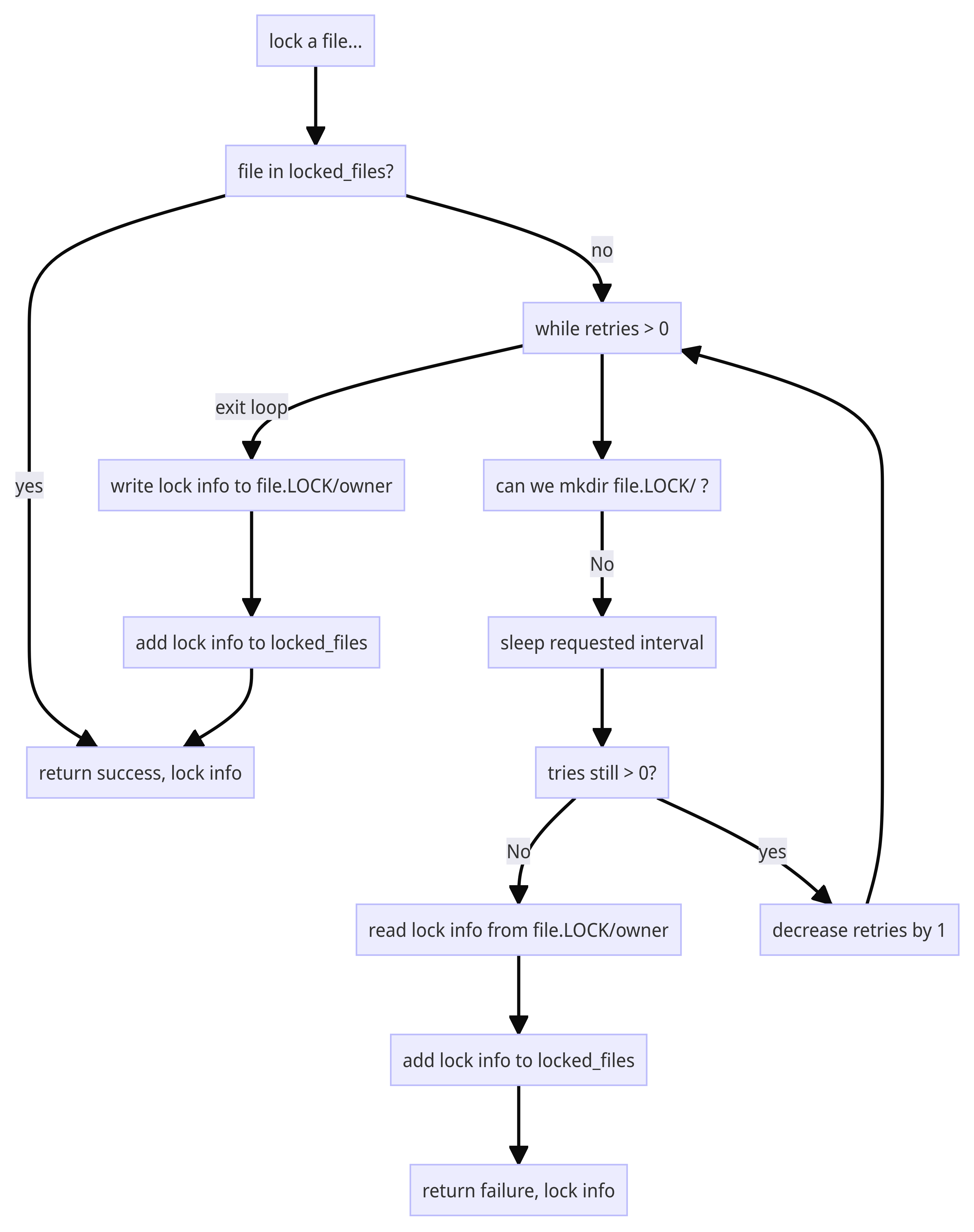
Edit races and locking
The wiki was a huge success. We were able to to move everything from the physical whiteboard to “Ed’s Whiteboard” the website. Unfortunately success came with a problem: we were updating the pages a lot, and very often we’d have an edit race:
- Alice starts editing a page.
- Bob starts editing the same page.
- Bob saves their changes.
- Alice saves their changes.
- Bob is confused because their edits aren’t there, but something else is. Did Alice remove their edits?
This was recoverable, as the “previous” version of the page had Bob’s changes, but there had to be a phone call or an email: “Alice, did you change my edits to X? You didn’t? OK, thanks!”, and then Bob had to look back through the page archive for his edits, copy them out, and then re-edit the page. In the meantime, Carol has started yet another set of edits, and after Bob makes his changes, Carol saves…lather, rinse, repeat.
On busy days, our “productivity tool” could end up being pretty unproductive for slow typists. We needed a way to serialize edits, and I came up with the idea of the edit lock. When a page was actively being edited, it was marked as locked (and by who) when someone else accessed it, even for read. This made it clear that editing was in progress and prevented edit races by simply not allowing simultaneous edits at all. Because the person editing the page was flagged, it was possible for a second person to call or email them to ask them to save and release the lock. This did have the problem that if someone started an edit and went to lunch or went home for the day, the page would be locked until they came back. This was fixed by adding a “break edit lock” feature that turned off Alice’s lock and allowed Bob to edit the page. The wiki emailed Alice to let her know that the edit lock had been broken.
This only worked because we had a limited number of users editing the wiki; it wouldn’t have worked for something the size of Wikipedia, for instance, but our site only had about a half-dozen active users who all knew each other’s phone numbers and emails. If someone had a page busy for an extended time, we generally called to ask them to save so someone else could edit — lock breaking was infrequent, and mostly only used when someone had had a machine crash while they were editing.
This was our primary project tracking tool up until around 2005, and it served us pretty well.
Fast-forward 25 years…
Tooling has improved mightily since 1997, or even 2005. GitHub, GitLab, JIRA…lots of options that integrate source control, bug tracking and even wikis for documentation. Every once in a while, though, a standalone wiki is handy to have. There are services that provide just wikis, such as Notion, but a wiki that provides both public and private access, for free, is hard to find.
I’m one of the DJs and maintainers at RadioSpiral (radiospiral.net), and we have a lot of station management stuff to track: artists who have signed our agreement (we are completely non-profit, so artists who have released their music under copyright have to waive their ASCAP/BMI/etc. rates so we don’t personally go broke having to pay licensing fees); URLs and ports for the listening streams; configurations to allow us to broadcast on the site; and lots more.
Some of this info is public, some very private — for instance, we don’t want to publish the credentials needed to stream audio to the station for just anybody, but having them at hand for our DJs is very useful. Putting all this in a wiki to make it easy to update and have it centrally located is a big plus, but that wiki needs what the old one at Goddard had: delineated access levels.
High-level project goals
- Get WebWebX working as a standalone application that doesn’t require extensive CGI configuration to work. The original WebWebX was tightly integrated with Apache, and required Apache configuration, adding of ScriptAlias, and a lot of other tedious work. Ideally, the new version should be as close to “install and run” as possible.
- Modernize the codebase; most importantly, add tests. WebWebX worked incredibly well for code without tests, but I no longer am so sure of myself! In addition, the HTML “templating” is all inline print() statements, and I’d really prefer to do this better.
- Convert the code to a contemporary stack with a minimum of requirements to install it. I’ve chosen Mojolicious because it’s quite self-contained. I did not choose Catalyst or Dancer; both of those are great, but they definitely require a lot more prerequisites to install.
- Make this project something that’s generally useful for folks who just want a controlled-access wiki that’s easy to install, easy to deploy, and easy to manage.
Ideally, I want something that can be deployed to Heroku or Digital Ocean by checking out the code, setting some environment variables, and running it. We’ll see how close I can come to this ideal with a Perl stack.